В последние годы большое распространение получили различного рода
интеллектуальные системы, выполняющие обработку текстов на естественном
языке (ЕЯ). Один из классов таких систем образуют информационно-поисковые
системы (ИПС), ориентированные на естественно-языковое общение
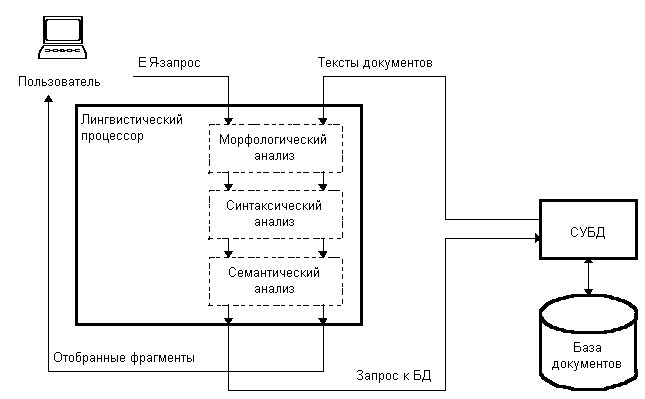
с пользователем. Общую схему такой ИПС можно представить следующим
образом:
Рис. 1
Одним из основных элементов ИПС является лингвистический процессор
(ЛП), выполняющий роль посредника между пользователем и базой
данных, в которой хранится интересующая его информация. Классическая
структура лингвистического процессора содержит три последовательных
блока - для морфологического, синтаксического и семантического
анализа текста.
Предмет данной работы - блок синтаксического анализа ЛП, предоставляющий
исходные данные для семантического анализатора и, как правило,
определяющий качество работы ЛП в целом.
Большинство систем анализа текстов на ЕЯ, использующих недетерминированные
методы синтаксического анализа, в той или иной форме опираются
на идею последовательной группировки слов, а затем и словосочетаний
исходного предложения в словосочетания более высокого уровня.
Формируемые словосочетания принято называть синтагмами. Слова
и синтагмы объединяются под общим термином "текстовые единицы"
(ТЕ). Правила образования синтагм из ТЕ и методика применения
этих правил определяют точность и скорость выполнения каждого
конкретного алгоритма синтаксического анализа.
В системах синтаксического анализа используются различные методы
представления информации о правилах образования синтагм; со времени
появления первых таких систем эти методы получили существенное
развитие.
Первые алгоритмы машинного синтаксического анализа (середина 60-х
гг.) использовали формально-декларативную синтагматику, что было
связано с развитием теории формальных языков и попытками ее использования
для описания ЕЯ. Декларативное описание синтагматики позволяет
полностью отделить описания синтагм от механизма синтаксического
анализа и за счет этого обладает существенными достоинствами :
Во-первых, оно позволяет использовать один и тот же механизм
анализа для различных естественных языков. Это особенно существенно
в системах машинного перевода.
Во-вторых, при разработке системы реализуется естественное
разделение труда между лингвистами и программистами.
В-третьих, возможно свободное редактирование и пополнение
используемой грамматики без изменений в механизме анализатора.
Этим обусловлено широкое применение декларативных методов описания
синтагм в ранних системах машинного перевода. Однако по мере развития
машинного синтаксического анализа проявились и недостатки этих
методов, связанные в первую очередь с их слабой адекватностью.
Другими словами, в рамках простых декларативных описаний невозможно
передать сложные языковые конструкции, а усложнение описаний неизбежно
приводит к тому, что общий механизм анализа оказывается не в состоянии
их реализовать. Как отмечалось в докладе П.Гарвина (1967 г.),
приходится либо адаптировать алгоритм анализа к конкретному синтагматическому
словарю, либо создавать второй алгоритм, который управлял бы первым
при движении по словарю. Неадекватность порождается, во-первых,
малым количеством лингвистической информации, выносимой в словарь
синтагм, и во-вторых - "оторванностью" механизма синтаксического
анализа от лингвистики.
Для преодоления неадекватности в последующих анализаторах пришлось
отказаться от чисто декларативного описания синтагматики и ввести
в словарь процедурную компоненту. Однако при этом достоинства
декларативных методов оказались во многом утрачены - прежде всего
из-за проблем реализации таких процедурных описаний при анализе.
В самом деле, при процедурном описании синтагматики разработчики
системы оказываются перед выбором : либо реализовать это описание
непосредственно в коде анализатора, либо вынести описание в словарь
и интерпретировать его записи-инструкции при выполнении анализа.
В первом случае описание синтагматики оказывается "намертво
зашитым" в исходный код программы-анализатора; синтагматического
словаря в этом случае не существует, а следовательно, все достоинства
декларативных описаний отсутствуют. Во втором варианте достигается
относительная независимость синтагматического словаря от механизма
анализа, однако возникает проблема скорости анализа - интерпретируемый
код словаря исполняется во много раз медленнее, чем процедуры,
откомпилированные вместе с программой-анализатором. Некоторые
из современных интеллектуальных систем пошли по первому пути,
например, французская SUSYII; большинство же использует
в той или иной форме второй подход.
Интересна в этом отношении разработка Е.И.Анно. В этой системе
процедуры оперирования с признаками ТЕ (а также алгоритмы их
группировки и т.д.) описаны на специально созданном метаязыке;
описания эти естественным образом отделены от механизма анализа
и образуют в совокупности синтагматический словарь. При таком
подходе обеспечивается открытость системы, удобство редактирования
грамматики и одновременно достигается высокая степень адекватности
описаний реальным языковым конструкциям. Однако остается проблема
быстродействия, поскольку описания на метаязыке приходится многократно
интерпретировать во время работы анализатора.
Описание разработки
Общие принципы
Представляется целесообразным попытаться совместить высокую скорость
анализа, характерную для компилируемых процедур, с удобством редактирования
и открытостью словаря, присущими интерпретируемым процедурным
описаниям. Одну из таких попыток представляет данная работа.
Очевидно, что высокого быстродействия синтаксического анализатора
невозможно добиться при использовании интерпретируемых правил.
Следовательно, система правил должна быть компилируемой, однако
при этом оставаться открытой для редактирования и не быть жестко
связанной с механизмом анализатора.
Этого можно добиться, если реализовать систему анализа, подобную
системе Е.И.Анно, и дополнить ее компилятором метаязыка. Этот
компилятор должен транслировать мета-описания синтагматического
словаря непосредственно в исполняемый код, включающий в себя проверку
требуемых условий и исполнение соответствующих действий. Всякий
раз после редактирования словаря его нужно перекомпилировать,
после чего изменения могут быть использованы анализатором. Однако
такой подход, во-первых, требует существенных затрат труда на
разработку компилятора, во-вторых, препятствует переносимости
системы на другие аппаратные платформы (для каждой из них потребуется
своя версия компилятора), и в-третьих, порождает проблемы при
стыковке кода механизма анализа с кодом компилированного словаря
(коды генерировались различными компиляторами).
Для решения проблемы предлагается использовать компилируемую систему
правил, реализованных на том же алгоритмическом языке, что и сам
механизм анализа, но принять специальные меры для разделения их
кода. Это позволит редактировать систему правил, не затрагивая
кода ни анализатора, ни той интеллектуальной системы, в которую
он встроен. Кроме того, предлагаются средства автоматизированного
создания синтагматических правил, которые позволят свести затраты
труда на программирование к минимуму; таким образом, пополнять
систему правил сможет профессиональный лингвист, которому достаточно
иметь весьма поверхностные представления о программировании. Эти
средства аналогичны по своим функциям таким CASE-средствам, как
Borland Delphi или AppExpert : по задаваемым пользователем условиям
они генерируют исходный текст для программной реализации создаваемого
правила. В идеале сгенерированный текст оказывается окончательным
и может не нуждаться в последующем редактировании; такое редактирование
может потребоваться для создания нестандартных правил.
Программная система, описываемая в данной работе, предназначена
прежде всего для экспериментальной отработки правил синтаксического
анализа. Она не ориентирована на непосредственное применение в
ИПС - такое применение будет иметь синтаксический анализатор,
отрабатываемый по мере ее развития. Это, в сущности, инструмент
разработчика. Следовательно, требования к открытости словаря и
удобству его редактирования предъявляются высокие - в отличие
от законченного анализатора, который будет работать с уже сформированным
словарем.
В идеале программа должна позволять вносить изменения в синтагматический
словарь без полной ее перекомпиляции или даже без выхода из программы,
что существенно ускорило бы отработку системы. И если первое условие
реализовать несложно, выделив текст всех правил в отдельный программный
модуль и определив для них единый программный интерфейс, то второе
условие уже требует определенных технических ухищрений. В частности,
можно реализовать словарь в виде внешней DLL-библиотеки, содержащей
функции-правила. При условии неизменности ее интерфейса библиотека
может быть перекомпилирована внешним компилятором типа BPC, BCC
по команде из основной программы, а затем вновь использована в
программе. Аналогичный подход можно применить и при программировании
в DOS.
По сравнению с описанием правил на метаязыке описание их на основном
языке программирования имеют как достоинства, так и недостатки.
Недостатком прежде всего является сложность и необходимость для
разработчика сочетать знание лингвистики с умением программировать.
Однако использование основного языка позволяет описывать правила
с максимальной гибкостью и точностью, в то время как любой метаязык
неизбежно накладывает свои ограничения. Кроме того, как уже отмечалось,
разработка мета-компилятора является отдельной достаточно трудоемкой
задачей, а для работы со словарем правил на основном языке используется
тот же компилятор, что и для механизма анализа. (Еще одной возможностью
является применение в качестве языка описания правил традиционного
Пролога или Лиспа, что и было сделано во многих синтаксических
анализаторах периода 70-х гг. Однако языки эти носят ярко выраженный
декларативный характер, а о низкой адекватности декларативных
описаний уже говорилось выше.)
И наконец, еще одно существенное преимущество основного языка
программирования перед Прологом и метаязыками. Речь идет об использовании
объектно-ориентированного проектирования (ООП) для создания правил.
Как будет показано ниже, ООП предоставляет для этого весьма удобные
и выразительные средства. Поскольку основными инструментальными
языками программирования до сих пор являются C++ и Object Pascal,
достаточно близкие между собой по идеологии ООП, то последующее
изложение можно в равной степени относить и к первому из них,
и ко второму. При необходимости будем пользоваться синтаксисом
Паскаля.
Объектно-ориентированное описание синтагматики
Многие системы синтаксического анализа в описании правил синтагматики
допускают группировку только двух ТЕ; некоторые имеют специальные
правила для группировки трех. Для сборки последовательности однородных
членов приходится применять еще более специализированные методы,
поскольку число однородных членов может быть различным. Обработка
пунктуации требует собственных механизмов - здесь число составляющих
также переменное. Другими словами, при анализе возникает необходимость
применения довольно разнотипных правил, отличающихся по виду проверяемых
условий, по количеству группируемых ТЕ, по взаимодействию с уже
примененными правилами и т.д. Для каждого "типа" правил
механизм анализатора должен обеспечить собственные средства поддержки,
что приводит к его неизбежному усложнению по мере пополнения словаря
правил. В существующих система анализа с этим приходится мириться;
усложнение механизма - естественная плата за повышение качества
анализа.
Использование ООП позволяет построить механизм анализа чрезвычайно
просто, на основе самых общих допущений о характере используемых
правил:
каждое правило должно принимать на вход массив последовательно
расположенных ТЕ и индекс в этом массиве, указывающий текущую
позицию в нем - другими словами, то место, в котором нужно попробовать
применить данное правило.
если правило успешно сработало, его результатом должна быть
новая ТЕ, которая будет объединять несколько ТЕ исходного массива.
каждое правило должно иметь ключ, определяющий очередность
применения правил.
Получив из сработавшего правила новую ТЕ, механизм анализа вставляет
ее в текущую позицию массива и одновременно удаляет из массива
все ТЕ, входящие в новую. На этом итерация заканчивается, и результирующий
массив готов для применения следующего правила (или того же самого
в новых условиях). При этом никаких допущений ни о характере проверяемых
условий, ни о количестве группируемых ТЕ, ни о правилах формирования
новой ТЕ механизм анализа не требует. (Более того, группируемые
ТЕ даже не обязаны располагаться последовательно.) Все, что требует
анализатор от очередного правила - "оценить обстановку и
в случае благоприятной обстановки примениться". Как конкретно
будет выполняться "оценка обстановки" и "применение",
для анализатора абсолютно не существенно.
Общая концепция построения системы выглядит так. Вводится базовый
объект ПРАВИЛО, содержащий поле КЛЮЧ и виртуальный метод РАБОТАТЬ.
Это абстрактный метод, во всех правилах-потомках он должен перекрываться.
Его и будет вызывать механизм анализа, обращаясь к очередному
правилу. Кроме метода РАБОТАТЬ, добавим еще метод ГРУППИРОВАТЬ,
поскольку действие любого правила подразумевает группировку. Он
может быть невиртуальным, поскольку все правила будут одинаковым
способом группировать отобранные ТЕ.
Таким образом, все создаваемые правила будут наследовать
поле КЛЮЧ и метод ГРУППИРОВАТЬ и полиморфно реализовывать
метод РАБОТАТЬ, инкапсулируя необходимые условия проверки
и вспомогательные параметры.
Иерархия потомков объекта ПРАВИЛО может быть достаточно разветвленной
и охватывать самые разнообразные синтаксические и пунктуационные
конструкции.
Например, простые системы синтаксического анализа наиболее часто
применяют правила для группировки двух ТЕ, расположенных последовательно.
При этом одну из группируемых ТЕ считают главной, а другую зависимой,
и формируемая ТЕ получает набор признаков, присущий главной ТЕ.
Условия группировки оперируют только с наборами признаков главной
и зависимой ТЕ, игнорируя признаки других ТЕ в предложении.
Введем объект ПРАВИЛО_ПАРЫ, порожденный от объекта ПРАВИЛО, и
построим его метод РАБОТАТЬ следующим образом. Пусть МАССИВ -
массив текстовых единиц, подаваемых на вход метода РАБОТАТЬ, а
ИНДЕКС - номер текущей позиции в нем. Тогда алгоритм метода РАБОТАТЬ
в упрощенной форме можно представить так :
если
УСЛОВИЕ_1 (МАССИВ [ИНДЕКС] ) и УСЛОВИЕ_2 (МАССИВ [ИНДЕКС+1] ) и УСЛОВИЕ_ПАРЫ (МАССИВ [ИНДЕКС], МАССИВ [ИНДЕКС+1])
то
НОВАЯ_ТЕ := ГРУППИРОВАТЬ (МАССИВ [ИНДЕКС],
МАССИВ
[ИНДЕКС+1])
иначе
НОВАЯ_ТЕ := Ж
Здесь УСЛОВИЕ_1 - абстрактная виртуальная функция, проверяющая
морфологические признаки первой группируемой ТЕ; УСЛОВИЕ_2 - аналогичная
функция для проверки признаков второй ТЕ; УСЛОВИЕ_ПАРЫ - виртуальная
функция, проверяющая взаимное соответствие признаков первой и
второй ТЕ.
Теперь можно программировать конкретные синтагматические правила
для группировки двух ТЕ. Они будут создаваться в виде объектов,
порожденных от объекта ПРАВИЛО_ПАРЫ. Для этого достаточно только
переопределить виртуальные функции УСЛОВИЕ_1, УСЛОВИЕ_2, УСЛОВИЕ_ПАРЫ.
Например, так :
ПРАВИЛО_ОПРЕДЕЛЕНИЯ = объект (ПРАВИЛО_ПАРЫ)
функция УСЛОВИЕ_1(ТЕ)
УСЛОВИЕ_1 := ТЕ .ЧАСТЬ_РЕЧИ = ПРИЛАГАТЕЛЬНОЕ или
ТЕ .ЧАСТЬ_РЕЧИ = ПРИЧАСТИЕ;
функция УСЛОВИЕ_2(ТЕ)
УСЛОВИЕ_2 := ТЕ .ЧАСТЬ_РЕЧИ = СУЩЕСТВИТЕЛЬНОЕ;
функция УСЛОВИЕ_ПАРЫ(ТЕ_1, ТЕ_2)
УСЛОВИЕ_ПАРЫ :=
ТЕ_1.ПАДЕЖ = ТЕ_2.ПАДЕЖ и ТЕ_1.ЧИСЛО = ТЕ_2.ЧИСЛО
и
(ТЕ_1.ЧИСЛО = МНОЖЕСТВЕННОЕ или ТЕ_1.РОД = ТЕ_2.РОД);
Если же потребуются правила, которые группируют две ТЕ, но в качестве
условий используют не только их признаки, но и признаки других
ТЕ в предложении, для таких правил нетрудно построить свой базовый
объект ОБЩЕЕ_ПРАВИЛО_ПАРЫ. Например, сделать его порожденным от
ПРАВИЛО_ПАРЫ, перекрыв метод РАБОТАТЬ:
если УСЛОВИЕ_ОБЩЕЕ (МАССИВ, ИНДЕКС)
то ПРАВИЛО_ПАРЫ . РАБОТАТЬ (МАССИВ, ИНДЕКС)
иначе НОВАЯ_ТЕ := Ж
и добавив абстрактную виртуальную функцию УСЛОВИЕ_ОБЩЕЕ.
Итак, с помощью всего трех объектов можно описать прототипы наиболее
часто используемых в синтаксическом анализе правил. Для "нестандартных"
правил, которые в традиционных описаниях синтагматики вызывают
трудности и требуют специальной поддержки в механизме анализа,
создадим соответствующие базовые объекты, порожденные от объекта
ПРАВИЛО : ПРАВИЛО_ОДНОРОДНЫХ, ПРАВИЛО_СКОБОК, ПРАВИЛО_ПРЯМОЙ_РЕЧИ
и т.д., переопределяя в каждом случае метод РАБОТАТЬ требуемым
образом. Например, "сборку" однородных членов можно
в простейшем случае реализовать так :
ПРАВИЛО_ОДНОРОДНЫХ = объект (ПРАВИЛО)
функция РАБОТАТЬ (МАССИВ , ИНДЕКС)
k := ИНДЕКС;
циклпока САМОСТ_ЧАСТЬ_РЕЧИ (МАССИВ[k])
и
(МАССИВ[k+1] = "," или
(МАССИВ[k+1].ЧАСТЬ_РЕЧИ = СОЮЗ и
МАССИВ[k+1].ТИП = СОЧИНИТЕЛЬНЫЙ)) и
ЭКВИВАЛЕНТНЫ (МАССИВ[k], МАССИВ[k+2])
k := k+2;
конец цикла
если k > ИНДЕКС
то НОВАЯ_ТЕ :=
ГРУППИРОВАТЬ (МАССИВ[ИНДЕКС], ... ,МАССИВ[k])
иначе НОВАЯ_ТЕ := Ж
;
Заметим, что совсем не обязательно для каждого правила описывать
собственный тип объекта. Возможны случаи, когда один и тот же
тип правила может быть использован для группировки сходных, но
не тождественных сочетаний. Для этого создается несколько экземпляров
такого правила, каждый со своим значением некоторых параметров,
уточняющих условия данного правила. Например, одно и то же правило
можно применить для сборки фрагментов <"> <любое
слово> <"> и <(> <любое слово> <)>,
если в конструкторе правила указывать, какие именно символы пунктуации
должен обрабатывать данный экземпляр.
Для того чтобы все описанные выше объекты-правила заработали,
необходимо выполнить процедуру инициализации списка правил. В
этой процедуре создается по одному экземпляру каждого правила
(или более одного - см. выше), и созданные объекты вставляются
в общий список, упорядоченный по убыванию поля КЛЮЧ. Из этого
списка механизм анализа будет поочередно их выбирать и применять
к текущему массиву ТЕ в ходе анализа. Поскольку значение поля
КЛЮЧ для любого экземпляра правила может быть программным путем
изменено, существует возможность произвольно менять очередность
применения правил без выхода из программы и даже непосредственно
в ходе анализа.
Реализация механизма многовариантного анализа
При использовании объектно-ориентированного описания синтагматики
основной цикл работы анализатора выглядит достаточно просто:
цикл
циклпо i от 1 до
КОЛИЧЕСТВО_ПРАВИЛ
циклпо k от 1 до
КОЛИЧЕСТВО_ТЕ
СПИСОК_ПРАВИЛ[ i ] . РАБОТАТЬ (МАССИВ_ТЕ, k);
если НОВАЯ_ТЕ N Ж
то ВСТАВИТЬ_НОВУЮ (НОВАЯ_ТЕ, МАССИВ_ТЕ, k);
конец_цикла k
конец_цикла i
пока НОВАЯ_ТЕ N Ж
Процедура ВСТАВИТЬ_НОВУЮ выполняет очевидную функцию: вставляет
в текущую позицию массива текстовых единиц новую ТЕ и удаляет
из него все ТЕ, вошедшие в новую. Процесс повторяется до тех пор,
пока на очередном шаге окажется невозможным применить хотя бы
одно правило. Если в этой ситуации МАССИВ_ТЕ содержит только одну
ТЕ, то анализ является успешным, а полученная ТЕ представляет
собой синтаксическую структуру всего предложения.
Однако известно, что синтаксическая интерпретация предложения
на ЕЯ в общем случае неоднозначна. Источником неопределенности
является, во-первых, возможная неоднозначность результатов предварительного
морфологического анализа (омонимия), а во-вторых - наличием в
естественном языке разнообразных конструкций, допускающих множественное
толкование. Существует немало языковых конструкций, которые не
могут однозначно интерпретироваться даже человеком (см. примеры
в [1],[2]). Следовательно, любой качественный синтаксический анализатор
должен обеспечивать не только построение законченного варианта
синтаксической структуры входного предложения, но и нахождение
всех допустимых ее вариантов.
Существует две основных стратегии многовариантного анализа. Одна
из них обозначается в зарубежных разработках как "breadth-first"
- "сначала в ширину" (перевод термина предложен в [1]).
При такой стратегии анализатор генерирует одновременно все возможные
связи между ТЕ предложения при всех допустимых его интерпретациях.
При этом, очевидно, результирующая совокупность связей или групп
окажется противоречивой, если хотя бы один фрагмент предложения
допускает более одной интерпретации. Извлекая из этой "паутины"
связей непротиворечивые подмножества, можно получать различные
варианты синтаксической структуры предложения или его фрагментов.
Другая стратегия, именуемая "depth-first" - "сначала
в глубину" (см. [1]), предусматривает не параллельное, а
последовательное получение вариантов синтаксической структуры.
Всякий раз, когда на очередном шаге анализа оказывается возможным
установить несколько взаимоисключающих связей между ТЕ, анализатор
выбирает одну из них, отбрасывая остальные. Будем называть такой
шаг точкой ветвления. Если после очередного шага анализатор зашел
в тупик (больше нельзя установить ни одной связи), то выполняется
возврат к последней точке ветвления и выбирается другая из возможных
альтернатив. Полностью анализ завершается после того, как все
возможные альтернативы во всех точках ветвления испробованы. Если
в очередном тупике удалось получить связную структуру предложения,
эта структура выдается на выход анализатора как один из возможных
вариантов разбора.
Вторая стратегия анализа позволяет косвенным образом влиять на
порядок обхода дерева альтернатив, а значит, на порядок, в котором
будут получены варианты разбора. Цель такого влияния - получение
"правильной" интерпретации как можно раньше, в идеале
самой первой. Этой идее было дано название "best-first"
- "лучший [вариант] первым". Для этого необходимо, чтобы
альтернативы в точках ветвления можно было как-то отсортировать
по предпочтительности.
В данной работе использована стратегия "depth-first",
причем порядок обхода дерева альтернатив определяется двумя факторами:
последовательностью применения правил (задается значениями полей
ПРАВИЛО. КЛЮЧ) и направлением движения анализатора по массиву
ТЕ (слева направо или справа налево). Опыты показали, что наиболее
часто в текстах документов, с которыми работает анализатор, встречаются
конструкции, требующие группировки справа налево. (Этот факт подтверждается
также в разработках Л.Г. Митюшина, используемых в нескольких отечественных
системах анализа.) Следовательно, при движении анализатора справа
налево шансы получить верную интерпретацию в числе первых увеличиваются.
Сам механизм обхода дерева вариантов реализован следующим образом.
Всякий раз, когда новая ТЕ вставляется в массив, этот факт фиксируется
в специальном протоколе анализа новой записью. Протокол имеет
вид стека, вершина которого содержит ссылку на последнюю из вставленных
ТЕ. Когда на очередном шаге анализатор оказывается в тупике, выполняется
процедура ОТКАТ. Эта процедура удаляет из массива текстовую единицу,
вставленную последней, восстанавливает в массиве все ее дочерние
ТЕ и делает пометку ОТБРОШЕНО в верхней записи протокола. Всякий
раз при создании новой ТЕ анализатор просматривает все записи
протокола, и если запись о такой ТЕ уже присутствует в нем с флагом
ОТБРОШЕНО, то эта ТЕ не будет вставлена в массив. Это гарантирует,
что ни одна ветвь дерева альтернатив не будет пройдена дважды.
Если при выполнении процедуры ОТКАТ запись в вершине стека уже
содержит флаг ОТБРОШЕНО, то эта запись выталкивается из стека.
Следовательно, соответствующая ТЕ вновь может быть создана и вставлена
в массив. Полная остановка анализатора происходит в тот момент,
когда после очередного выполнения процедуры ОТКАТ протокол окажется
пустым. Это будет означать, что все допустимые в предложении ТЕ
уже были испробованы, отброшены и удалены из стека. Формально
алгоритм отката можно записать так:
циклпока ПРОТОКОЛ.НЕ_ПУСТ и
ВЕРХНЯЯ_ЗАПИСЬ.ОТБРОШЕНО
ПРОТОКОЛ . УДАЛИТЬ_ВЕРХНЮЮ ;
конеццикла ;
если ПРОТОКОЛ.НЕ_ПУСТ
то ВЕРХНЯЯ_ЗАПИСЬ.ОТБРОШЕНО := TRUE ;
ОТМЕНИТЬ (МАССИВ_ТЕ , ВЕРХНЯЯ_ЗАПИСЬ);
конецесли
Чтобы использовать основной цикл работы анализатора, описанный
в начале раздела, в условиях работы с откатами, необходимо, во-первых,
заставить функцию ВСТАВИТЬ_НОВУЮ выполнять проверку вставляемой
ТЕ на "отброшенность" и регистрировать новую ТЕ в
протоколе, и во-вторых, определить возможность отката :
цикл ОСНОВНОЙ_ЦИКЛ ;
если КОЛИЧЕСТВО_ТЕ = 1
то СОХРАНИТЬ_РЕЗУЛЬТАТ ( МАССИВ_ТЕ [1] );
ОТКАТ ;
пока ПРОТОКОЛ.НЕ_ПУСТ
Таким образом, каждую создаваемую группу анализатор рассматривает
как потенциальную точку ветвления, причем разветвление альтернатив
всегда бинарное: либо создавать такую ТЕ, либо не создавать. Обе
ветви будут гарантировано пройдены до конца. Это может приводить
к повышенным затратам машинного времени, но во-первых, позволяет
избежать взаимной проверки создаваемых групп на противоречивость
в очередной точке ветвления, а во-вторых, гарантирует полноту
перебора возможных вариантов.
Техническая реализация описанного выше алгоритма может выдавать
варианты анализа по одному, всякий раз возвращаясь в вызывающую
программу после формирования очередного варианта. Это позволяет
прекратить анализ, как только будет получена первая интерпретация,
приемлемая с точки зрения основной программы. Обычно в интеллектуальных
системах, работающих с текстом, результаты синтаксического анализа
обрабатываются семантическим анализатором. В нашем случае под
"приемлемостью" понимается успешная обработка семантическим
анализатором данного варианта синтаксической структуры предложения.
Автоматизированное программирование правил
Для облегчения создания и отладки новых синтагматических правил
предлагается использовать программный модуль, способный генерировать
прототип исходного кода для создаваемого объекта-правила. Для
"стандартных" правил, например, группирующих две последовательные
ТЕ, цепочку со знаками препинания или другую сравнительно простую
конструкцию, код получается вполне завершенным и работоспособным.
Например, при создании правила группировки двух ТЕ пользователь
с помощью диалогового окна выбирает часть речи и/или синтаксическую
роль каждой из них, а затем отмечает те постоянные и переменные
морфологические признаки, которыми они должны обладать. Допускается
произвольное сочетание этих признаков (по И, по ИЛИ, комбинированное).
Кроме того, пользователь вводит название нового правила и среди
двух ТЕ выбирает главную. После этого программа выдает на экран
текст на языке Object Pascal, реализующий новое правило. Этот
текст может быть тут же отредактирован (в случае необходимости
и при наличии у пользователя навыков программирования) и переписан
непосредственно в файл с исходным кодом правил анализа.
Заключение
Объектно-ориентированный подход к описанию синтагматики позволяет
максимально упростить механизм синтаксического анализатора при
сохранении высокой степени адекватности, присущей процедурным
синтагматическим описаниям. Техническая реализация описанного
подхода может сочетать высокое быстродействие анализатора с открытостью
системы правил для пополнения и редактирования. Создание новых
правил-объектов может быть автоматизировано на основе диалоговых
CASE-средств; таким образом, работа с системой правил не будет
требовать профессионального умения программировать .
Литература
1. Компьютерный синтаксический анализ: описание моделей и направлений
разработок.- Г. Д. Карпова, Ю. К. Пирогова, Т. Ю. Кобзарева, Е.
В. Микаэлян. // Итоги науки и техники (серия "Вычислительные
науки"). Т.6. -М.: ВИНИТИ, 1991.
2. Перспективы развития вычислительной техники: В 11 кн.: Справ.
пособие / под ред. Ю. М. Смирнова. Кн. 2. Интеллектуализация ЭВМ
/ Е. С. Кузин, А.И. Ройтман, И. Б. Фоминых, Г. К. Хахалин. - М.:
Высш. шк., 1989.
3. Искусственный интеллект. - В 3-х кн. Кн.1. Системы общения
и экспертные системы: Справочник. /Под ред. Д.А.Поспелова. -М.:
Наука, 1990.
4. Искусственный интеллект. - В 3-х кн. Кн.2. Модели и методы:
Справочник. /Под ред. Д.А.Поспелова. -М.: Наука, 1990.
5. Попов Э.В. Общение с ЭВМ на естественном языке. -М.: Наука,
1982.
6. Анно Е.И. К типологии алгоритмов синтаксического анализа
(для формальных моделей естественного языка).
-НТИ, Сер. 2., 1980.- N3, с.15-22.
7. Гарвин П. Алгоритм синтаксического анализа "Фулькрум"
(для русского языка) // Автоматический перевод. -М.: Прогресс,
1971, с. 26-40.
8. Буч Г. Объектно-ориентированное проектирование с примерами
применения. -К.: Диалектика, 1993.