Андреев А.М., к.т.н., доц. МГТУ им. Н.Э.Баумана Березкин Д.В., к.т.н., директор НПЦ Интелтек Плюс Брик А.В., аспирант МГТУ им. Н.Э.Баумана Тел. 177-35-11
для информационно-поисковой системы |


|
Смеще-ние |
Длина |
Название поля |
Содержание |
Примечание |
|
0 |
25 байт |
TheWord |
Текст основы |
Для слов-исключений нулевой байт содержит символ *, |
|
25 |
1 байт |
Part |
Части речи |
См. Табл. 3 |
|
26 |
6 байт |
Signs |
Постоянные |
См. Табл. 3 |
|
32 |
28 байт |
SemLinks |
Семантические ссылки |
При морфологическом анализе не используются |
Табл.1. Структура полей в записи основы
Если часть речи, определяемая полем Part, является изменяемой, то нулевой байт поля Signs (смещение 26) содержит номер типа аффиксов, соответствующий данной основе. Все типы аффиксов хранятся в другом словарном файле — ENDINGS.TBL. Это текстовый файл в кодировке Windows (кодовая страница ANSI 1251), содержащий разделы следующего вида:
[часть речи]
1. -аффикс_1, -аффикс_2, ... , -аффикс_К ;
2. -аффикс_1, ... , ... , -аффикс_К ;
...
35. -аффикс_1, ... , ... , -аффикс_К ;
Здесь [часть речи] — название части речи, к которой относятся перечисляемые в этом разделе типы аффиксов. Например, [СУЩЕСТВИТЕЛЬНЫЕ], [ПРИЛАГАТЕЛЬНЫЕ] и т. д. Некоторые части речи могут использовать один и тот же раздел. Например, прилагательные, причастия и порядковые числительные используют общий раздел [ПРИЛАГАТЕЛЬНЫЕ], поскольку эти части речи имеют сходные типы аффиксов. После имени раздела следуют пронумерованные строки, каждая из которых определяет один тип аффиксов. Номер строки и есть номер типа аффикса, содержащийся в нулевом байте поля Signs в записи основы. После номера строки следуют цепочки символов “-аффикс_1”, “-аффикс_2” и т. д., являющиеся аффиксами словоформы во всех возможных вариантах ее изменения. Число аффиксов в строке свое для каждой части речи; оно равняется числу возможных словоформ для нее. Например, для существительных таких цепочек-аффиксов будет 12, поскольку существительные могут изменяться по шести падежам и двум числам.
Особым образом морфологическая подсистема ЛП обрабатывает слова-исключения, то есть слова, у которых неизменной основы нет. Такие слова хранятся в отдельном файле исключений EXEPTION.TBL. Этот файл имеет точно такой же формат, что и файл аффиксов ENDINGS.TBL, но вместо аффиксов в нем содержатся полные словоформы. Формальные основы для таких слов-исключений хранятся в общем файле основ BASES.TBL, однако поле TheWord в этих записях начинается с символа *, который является признаком исключения. За ним следуют два байта, содержащие номер строки в файле исключений, соответствующей данному слову.
При инициализации морфологического анализатора выполняется загрузка файла BASES.TBL в соответствующий динамический массив, а при закрытии — сохранение массива в этом файле. Таким образом, все операции со словарем основ во время работы анализатора выполняются без обращения к диску. Используемый динамический массив может хранить не более 16383 элементов; именно эта цифра и определяет то наибольшее количество основ, с которым может работать лингвистический процессор. Суммарный объем памяти, необходимой для хранения словаря основ, при этом не превышает 60 * 16383 = 982980 байт, что вполне допустимо при работе в среде Windows. Заметим, что число 16383 ограничивает только количество основ, а не словоформ; каждая основа может порождать одну или несколько словоформ в зависимости от части речи (для существительного — 12, для прилагательного — 24, для глагола — 10 и т. д.). Таким образом, общее число словоформ в морфологической подсистеме реализованного ЛП может достигать примерно 100 000.
Файлы ENDINGS.TBL и EXEPTION.TBL также загружаются в память во время инициализации блока морфологического анализа. В памяти они хранятся в виде двух массивов текстовых строк, считанных из соответствующих файлов. Такая форма хранения, безусловно, не является оптимальной по скорости доступа и занимаемому объему памяти, но зато наиболее удобна при редактировании морфологического словаря, а главное — обеспечивает единообразное представление аффиксов для всех частей речи, сколько бы возможных форм они не имели.
Доступ к морфологическому словарю
Для просмотра, редактирования, добавления и удаления записей в морфологическом словаре модуль доступа (ДО) содержит специальное диалоговое окно, реализованное в файле MORPHDLG.PAS. В левой части этого окна отображается список всех основ, в правой — постоянные морфологические признаки для выбранной в левом списке основы. Кроме морфологических признаков, окно показывает также все возможные словоформы для выбранной основы.
Окно может работать в двух режимах — просмотра и редактирования. В режиме просмотра изменение морфологических признаков основы запрещено; это снижает вероятность случайного внесения неверных данных в словарь. В режиме редактирования пользователю предоставляется возможность изменять любые параметры выбранной основы, в том числе часть речи и текст самой основы. При изменении части речи автоматически обновляются названия и списки возможных значений для других морфологических признаков. Переход из режима редактирования назад в режим просмотра возможен как с сохранением сделанных изменений, так и без сохранения.
Доступ к словарю аффиксов и исключений возможен только из режима редактирования. Для этого служит кнопка “Список”, расположенная в правой части диалогового окна. При нажатии кнопки открывается окно с таблицей, содержащей все присутствующие в словаре типы аффиксов для данной части речи. (Элементы таблицы недоступны для редактирования и удаления, поскольку на каждый из них ссылается несколько основ из словаря, и пользователю сложно отследить, как повлияет изменение одного аффикса на все их словоформы. Удаление же строки из таблицы сделает полностью бессмысленными те основы, которые на этот тип аффиксов ссылались).
Иногда при пополнении словаря основ возникает ситуация, когда ни один из присутствующих типов аффиксов не соответствует новой основе. В таких случаях пользователю предоставляется возможность добавления нового типа аффиксов. При этом к таблице добавляется еще одна строка, доступная для редактирования. После ввода всех аффиксов нового типа пользователь должен нажать кнопку “Сохранить”. Теперь новая строка внесена в словарь, и любые основы соответствующей части речи могут на нее ссылаться. Изменить эту строку больше не удастся.
Аналогично обстоит дело и при вводе слов-исключений.
Для вывода на экран результатов морфологического анализа модуль ДО содержит окно просмотра, реализованное в файле MORRES.PAS. Окно содержит два списка. В левом списке перечислены все текстовые единицы (слова, числа, знаки препинания), найденные в анализируемом фрагменте. Правый список показывает, какие интерпретации возможны для выделенной в левом списке лексической единицы.
Окно не является модальным, поэтому пользователь может просматривать результаты морфологического разбора одновременно с другими операциями — например, выполнением синтаксического или семантического анализа.
Для удобства просмотра размеры окна можно изменять. При этом размеры обоих списков автоматически приводятся в соответствие с новыми размерами окна просмотра.
Обзор различных методов построения синтаксического анализатора для текстов на естественном языке, а также подробное описание концепции анализатора, реализованного в данном проекте, приводятся в [1]. Здесь же коротко перечислим основные особенности реализованного блока синтаксического анализа :
- многовариантный анализ с последовательной выдачей вариантов;
- возможность изменения последовательности выдачи вариантов;
- возможность введения ограничений на время выполнения анализа;
- выдача частичных вариантов разбора при невозможности сформировать ни одного полного варианта;
- отсутствие ограничений на тип условий, проверяемых правилами синтагматики, а также на действия, выполняемые правилами;
- использование в качестве синтагматического словаря файла с исходными текстами правил анализа, записанными на языке Object Pascal;
- возможность автоматически генерировать исходные тексты для вновь создаваемых правил анализа;
- реализация в виде отдельной DLL-библиотеки, допускающей перекомпиляцию без выхода из основной программы.
Блок синтаксического анализа реализован в файлах SYNTAX.PAS и RULES.PAS. Первый из них реализует поддержку общих механизмов синтаксического анализатора, а второй — описания конкретных правил, используемых при анализе. Таким образом, файл RULES.PAS можно рассматривать как своего рода “словарь” правил синтагматики.
Анализатор позволяет использовать две основных стратегии, отличающиеся последовательностью применения правил — а значит, и последовательностью обхода дерева вариантов разбора.
При анализе “по приоритетам” на очередной итерации выбирается одно рабочее правило и делается попытка его применения поочередно в каждой позиции анализируемого предложения. Как только применение правила окажется успешным, перебор правил начинается сначала. Последовательность использования правил анализа задается жестко с помощью системы приоритетов: чем выше приоритет данного правила, тем раньше оно будет испробовано. Отдельные правила можно временно “выключать” из анализа, устанавливая их приоритет равным нулю.
Другая стратегия анализа — ”по порядку слов” — опирается на последовательность слов в анализируемом предложении. На очередной итерации устанавливается фиксированная рабочая позиция в предложении, и в этой позиции поочередно испытываются все правила анализа. Как только одно из правил сработает, обход предложения начинается сначала. (Последовательность применения правил в рабочей позиции определяется той же системой приоритетов.)
Эти две стратегии синтаксического анализа были реализованы с целью их сравнения и выбора из них наиболее эффективной, то есть той стратегии, которая первой приводит к получению верной (с точки зрения человека) интерпретации предложения в большинстве случаев. Однако опыт работы с синтаксическим анализатором не позволил автору однозначно предпочесть какую-либо из них. Поэтому в данной версии лингвистического процессора сохранены обе стратегии.
Начинается работа синтаксического анализатора с инициализации списка правил (т.е. его сортировки по приоритетам) и очистки протокола. Протокол — вспомогательная структура данных типа стек, которую анализатор использует для регистрации формируемых им текстовых единиц. (Как уже говорилось в [1], каждая сформированная текстовая единица (ТЕ) потенциально является узлом дерева альтернатив синтаксической структуры. Регистрация этих узлов позволяет гарантировать, что никакая ветвь дерева альтернатив не будет пропущена или пройдена дважды.)
Затем в соответствии с выбранной стратегией анализатор пытается применять имеющиеся в списке правила в различных позициях предложения. На блок-схеме переменная НомерСлова означает текущую рабочую позицию в анализируемом предложении, переменная ЧислоСлов — количество текстовых единиц верхнего уровня в нем, переменная Правило — текущее правило анализа. Признаком успешности применения этого правила является значение переменной НоваяТЕ, отличное от нуля. Всякий раз, когда применение правила оказалось успешным, в Протокол заносится значение переменной НоваяТЕ. Кроме того, в результате успешной работы любого правила уменьшается значение переменной ЧислоСлов, поскольку любое правило объединяет несколько текстовых единиц в одну.
Когда все правила во всех рабочих позициях испробованы, процедура анализа завершается. Если при этом оказывается, что ЧислоСлов = 1, то это означает, что анализ выполнен полностью. Эта единственная ТЕ содержит в себе вариант синтаксической структуры исходного предложения. Если же ЧислоСлов > 1, значит, полную синтаксическую структуру предложения сформировать не удалось, и присутствующие в массиве ТЕ являются структурами фрагментов исходного предложения. В обоих случаях сформированный массив ТЕ передается в вызывающую подпрограмму в качестве результата анализа (на блок-схеме это отображено блоком “Сохранить результат”).
Поскольку синтаксический анализ больших предложений может занимать достаточно продолжительное время, механизм анализатора предусматривает возможность принудительного ограничения времени анализа. Если к моменту истечения этого времени сформировать синтаксическую структуру предложения не удалось, анализатор выдает на выход “лучший” из всех частичных вариантов, которые ему удалось найти. В качестве лучшего берется вариант, содержащий наименьшее число текстовых единиц верхнего уровня.
Исходными данными для работы синтаксического анализатора является массив результатов морфологического анализа. В ходе анализа основным элементом данных является текстовая единица (ТЕ).
На этапе инициализации синтаксического анализатора для каждой записи омонима (взятой из массива результатов морфологического анализа) формируется одна элементарная ТЕ. (Будем называть текстовую единицу элементарной, если она не содержит других ТЕ. После этого элементарные ТЕ разбиваются на группы в соответствии с массивами омонимов, для которых они сформированы. Все элементарные ТЕ, относящиеся к одному массиву омонимов, объединяются в общий массив-“контейнер”. Последовательность массивов-контейнеров объединяется в “синтаксический массив”, который и образует исходное синтаксическое представление для анализируемого предложения.
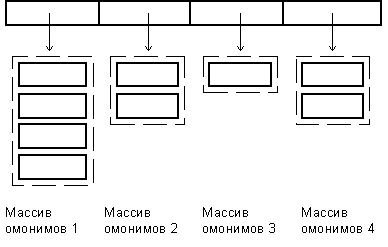
Сразу после инициализации синтаксический массив имеет структуру, полностью изоморфную структуре массива результатов морфологического анализа:

Рис.6. Синтаксический массив перед началом анализа
В ходе выполнения анализа каждое правило при соблюдении некоторых условий производит группировку двух или нескольких контейнеров (обычно соседних) в контейнер высшего уровня. Однако все условия правил оперируют непосредственно с признаками ТЕ, а не с контейнерами, в которых эти ТЕ содержатся. Поэтому возможна ситуация, когда для одних ТЕ из данного контейнера условие выполняется, а для других нет. В таких случаях условие считается верным и группировка осуществляется, однако из группируемых контейнеров удаляются все ТЕ, для которых условие не выполняется. Пусть, к примеру, некоторое правило применяется в первой позиции приведенного выше синтаксического массива. Правило содержит условие группировки, которому в синтаксическом массиве удовлетворяют пары [ТЕ 1.1, ТЕ 2.1], [ТЕ 1.3, ТЕ 2.2] и [ТЕ 1.4, ТЕ 2.2]; при этом первая группируемая ТЕ является главной. В результате применения этого правила синтаксический массив примет вид:
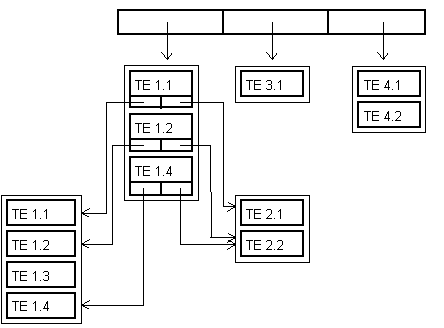
Рис.7. Синтаксический массив после операции группировки
После такой группировки текстовая единица ТЕ 1.3 оказалась исключенной из общей синтаксической структуры.
Что касается форматов словарной поддержки синтаксического анализа, то понимаемый в обычном смысле синтагматический словарь здесь отсутствует. Все правила хранятся оттранслированными непосредственно в машинный код в составе библиотеки синтаксического анализатора SYNT.DLL. Однако файл с исходным текстом всех правил анализа RULES.PAS входит в комплект поставки лингвистического процессора и может быть модифицирован пользователем, а сама библиотека организована таким образом, что может быть перекомпилирована без выхода из основной программы (см. раздел “Интерфейс пользователя”). В итоге файл RULES.PAS может рассматриваться как своего рода “словарь” правил; от традиционного словаря синтагматики его отличает только то, что он написан на языке Object Pascal и что после модификации его необходимо перекомпилировать.
Файл содержит четыре основных части.
Первая из них представляет собой обычную интерфейсную часть модуля на языке Object Pascal. Она содержит декларацию базового объекта TRule и служебных функций InitRuleList и DoneRuleList.
Вторая часть содержит декларацию объектов для всех конкретных правил анализа. Поскольку использование этих объектов за пределами модуля RULES не допускается, эта часть помещена в раздел Implementation. Чтобы утилита автоматического создания правил RuleExpert могла легко найти эту часть в тексте файла, часть завершается специальным комментарием {RXP_DECLARE}.
Третья часть содержит реализацию служебных функций InitRuleList и DoneRuleList. Первая из них создает рабочий список правил, вторая уничтожает его. Доступ к тексту функции InitRuleList также необходим утилите RuleExpert, поэтому этот текст отмечен специальным комментарием {RXP_INIT}.
Основная, четвертая часть включает в себя реализацию методов для всех объектов-правил, в том числе и для базового объекта TRule. Эта часть и представляет собой в чистом виде словарь синтагматических правил, записанных на языке Object Pascal. Для доступа утилиты RuleExpert к этой части она содержит специальный комментарий {RXP_IMPLEMENT}.
Для настройки синтаксического анализатора в программе предусмотрено соответствующее диалоговое окно (файл RCFG.PAS). Оно позволяет задавать приоритет каждого правила (целое число от 0 до 255; при значении 0 правило не используется), выбирать одну из двух стратегий анализа, а также устанавливать лимит времени на выполнение синтаксического анализа. Установленные значения могут быть сохранены в файле конфигурации LP.CFG.
Кроме того, пользователю предоставляется возможность написания собственных правил синтаксического анализа. Для этого предназначена кнопка “Новое...” . При нажатии на нее появляется окно утилиты RuleExpert, в котором пользователь вводит название нового правила, его краткое описание (по описанию его можно будет найти в списке правил), а также выбирает тип правила: общего вида, шаблонное или парное. Затем для шаблонного правила потребуется ввести шаблон, т.е. представить группируемый фрагмент в виде некоторой формулы, содержащей идентификаторы и знаки препинания. Например, шаблон
А : “ В “
может использоваться в правиле, группирующем фрагмент с прямой речью.
Необходимо также указать, какие условия будут проверяться в данном правиле. Они могут быть внешними (зависят от всех ТЕ в предложении) или внутренними (зависят только от группируемых ТЕ). Внутренние условия делятся на частные (зависят от параметров одной ТЕ) и взаимные (определяются взаимным соответствием группируемых ТЕ).
Выбрав тип условий, пользователь нажимает кнопку “Генерация”. Затем при наличии шаблона или частных условий появляется диалоговое окно с приглашением ввести условия по каждой ТЕ. Эти условия включают в себя ограничения на часть речи, морфологические признаки, синтаксическую роль.
После ввода всех условий программа создает три фрагмента исходного текста: декларацию объекта, его реализацию и включение в общий список правил. Каждый фрагмент может быть просмотрен и отредактирован пользователем в отдельном окне текстового редактора. Закончив редактирование, пользователь нажимает кнопку “Выход” и возвращается в окно настройки. При этом новые фрагменты текста добавляются в файл RULES.PAS.
Если теперь нажать кнопку “Выход” в окне настройки, программа вызовет компилятор DCC.EXE, который выполнит перекомпиляцию библиотеки SYNT.DLL с обновленным файлом RULES.PAS. Если компиляция прошла успешно, при повторном открытии окна настройки новое правило будет присутствовать в списке. В противном случае пользователю выдается сообщение об ошибке, и файл RULES.PAS восстанавливается из архивной копии.
Диалоговое окно для просмотра результатов синтаксического анализа (файл SRES.PAS) сделано немодальным. Оно выводит на экран древовидный список, изображающий синтаксическую структуру, которая сформирована анализатором на данной итерации. Любую нетерминальную ТЕ в списке можно “свернуть” или “развернуть” (спрятать или показать дочерние ТЕ), чтобы проверить правильность структуры на всех уровнях. Размеры списка автоматически изменяются при изменении размеров окна.
При нажатии кнопки “Следующий” анализатор находит следующий вариант синтаксической структуры и выводит его на экран. Если других вариантов нет, об этом выдается предупреждающее сообщение.
Кнопка “Первый” позволяет вернуть анализатор в исходное состояние и начать анализ с первого варианта. Это требуется в тех случаях, когда правильный вариант был случайно пропущен пользователем.
Если ни одного полного варианта синтаксической структуры найти не удалось, список будет содержать несколько не связанных между собой фрагментов. При этом кнопки “Следующий” и ”Первый” недоступны.
Наиболее простым и универсальным средством представления знаний в системах искусственного интеллекта является семантическая сеть. В общем случае она представляет собой ориентированный граф, вершины которого обозначают сущности (объекты), а ребра — отношения (связи) между ними. Имена вершин и ребер обычно совпадают с именами соответствующих сущностей и отношений, используемыми в естественном языке. Ребро и две связываемые им вершины представляют минимальную смысловую информацию — факт наличия связи определенного типа между соответствующими объектами.
По роду хранимой информации выделяют два типа семантических сетей: А-сети (концептуальные, интенсиональные) и К-сети (фактуальные, экстенсиональные). Первые содержат множество объектов и отношений, допустимых в данной предметной области; вторые — множество объектов и отношений, присутствующих в описании конкретной ситуации.
Для выделения в семантической сети некоторых законченных фрагментов используется понятие семантического пространства. Это понятие аналогично скобкам в математике. Если представить семантическую сеть в виде кортежа
S = <V,U> ,
где V — множество вершин, U — множество ребер, то семантическое пространство можно обозначить как
P = <W,U`> ,
где W = {V`,{Pi}}, U`НU, V`НV, {Pi} — множество всех семантических пространств, вложенных в пространство P.
Задачей семантического анализатора ЛП является преобразование синтаксического дерева зависимостей в соответствующий фрагмент К-сети. При этом может выполняться проверка допустимости каждого семантического отношения по опорной А-сети. (Сразу отметим, что для работы с реальными документами объем такой А-сети будет весьма велик, и она потребует больших затрат времени на создание и поддержку. В данном проекте механизм сверки с опорной сетью не реализован; поскольку анализируемые документы предполагаются заведомо корректными, такая сверка не является необходимой.)
Кроме того, семантический анализатор должен уметь находить связи между семантическими сетями отдельных предложений в документе — другими словами, анализировать референциальные отношения (см.[8], гл.3).
Очевидно, полная реализация семантического анализа — задача чрезвычайно трудоемкая. В текущей версии разработанного программного продукта обрабатываются только несколько наиболее простых смысловых конструкций, близких к своему синтаксическому представлению. Каждое предложение анализируется отдельно; средства “стыковки” фрагментов сети между собой в общую сеть документа пока не реализованы.
Тем не менее, реализованная часть семантического анализатора способна выявлять некоторые ошибки синтаксической структуры (например, связанные с неверной моделью управления); таким образом, существует обратная связь между семантическим и синтаксическим анализом — необходимое свойство ЛП, ради которого в некоторых разработках ЛП эти два этапа анализа выполняются совместно в общем аналитическом блоке.
Согласно [6], из множества слов русского языка по семантическим признакам можно выделить следующие категории:
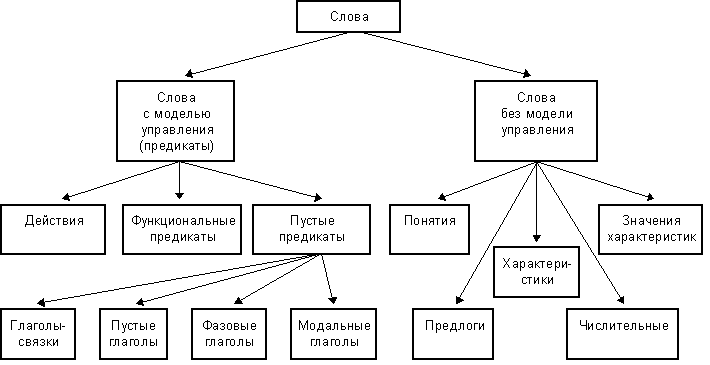
Рис. 8. Классификация слов русского языка по семантическим категориям
Для лингвистического процессора, предназначенного для работы в составе ИПС, наиболее важной является обработка предикатов действия и их возможных актантов — понятий, характеристик и их значений, а также числительных. Обработка функциональных и пустых предикатов может быть сведена к модификации фрагментов семантической сети, построенных для зависящих от них предикатов действия.
Каждый предикат имеет одну или несколько моделей управления (МУ). Модель управления накладывает синтаксические и семантические условия на возможные актанты (аргументы) данного предиката и указывает их семантические роли по отношению к предикату. В упрощенном виде МУ можно представить как таблицу, каждая строка в которой определяет один из возможных актантов. Эта строка содержит: предлог (если есть), часть речи и падеж актанта, его семантическое метапонятие (категорию), семантическую роль в предикате и признак обязательности данной роли.
Анализ моделей управления позволяет естественным образом перейти от синтаксического дерева зависимостей к фрагменту семантической сети. Для этого в простейшем случае достаточно: 1) для каждого предиката отыскать в дереве зависимостей все присутствующие актанты; 2) создать по одной вершине на каждый актант и еще одну — для самого предиката; 3) провести от вершины-предиката дугу к каждой вершине-актанту; при этом имя дуги (ее семантическая роль) выбирается из модели управления в зависимости от актанта. Если модель управления не допускает такого актанта ни в одной семантической роли, остается две возможности: либо данная ТЕ в действительности является по отношению к предикату не актантом, а обстоятельством (тогда эту связь можно отобразить дугой соответствующего типа), либо имеет место ошибка синтаксической структуры.
Правильно различать эти два случая удается не всегда, однако можно указать условие, при котором с большой вероятностью присутствует именно ошибка синтаксической структуры. Имеется в виду ситуация, когда актант удовлетворяет морфологическим условиям модели управления, а семантическим — нет. Поскольку синтаксический анализатор при группировке не проверяет семантические признаки, он не может самостоятельно обнаруживать ошибки такого типа. Таким образом, если ошибка обнаружена на этапе семантического анализа, необходимо вернуться назад к синтаксическому анализу и попытаться найти другой вариант синтаксической структуры, который бы не содержал неверного актанта в поддереве зависимостей данного предиката. Для того чтобы синтаксический анализатор не пытался снова объединить предикат с неверным актантом, в ТЕ-предикате и ТЕ-актанте устанавливается специальный флаг ошибки.
В итоге обработка предикатов действия может быть представлена в виде следующей схемы:
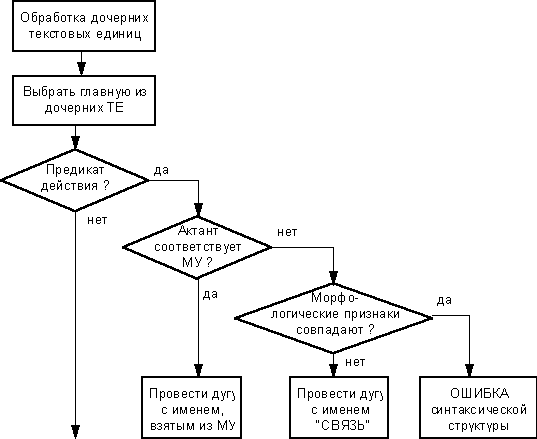
Рис.9. Блок-схема обработки предикатов действия
При обработке понятий рассматриваются только несколько наиболее распространенных синтаксических конструкций.
В частности, интерес представляет конструкция из нескольких последовательных существительных в родительном падеже. Каждое из них может быть понятием, характеристикой или значением характеристики. Если два понятия стоят рядом, и второе из них — в родительном падеже (например, УКАЗ ПРЕЗИДЕНТА), то чаще всего подразумевается отношение “принадлежности” первого понятия второму. Если зависимая ТЕ является понятием, а главная — характеристикой (например, ПРОДОЛЖИТЕЛЬНОСТЬ ДОКЛАДА), то, во-первых, между ними можно провести отношение “характеристика”, а во-вторых, обычно присутствует еще одна или несколько ТЕ типа значение характеристики, которые относятся к данной характеристике; такие отношения в семантической сети можно отобразить ребрами с именем “значение” (например, ПРОДОЛЖИТЕЛЬНОСТЬ ... — 15 МИНУТ).
При семантическом анализе составных числительных создается одна вершина, которая содержит общее численное представление для всех числительных, входящих в данную ТЕ (например, для фрагмента ПЯТЬ ТЫСЯЧ ДВЕСТИ ПЯТНАДЦАТЬ создается вершина, содержащая число 5215).
Если главная ТЕ является числительным, а зависимая — понятием или значением характеристики, то между ними проводится отношение “количество” (для количественных числительных) или “атрибут” (для порядковых). Часто такие фрагменты встречаются при описании дат, однако смысл передается совершенно иной, поэтому имеет смысл обрабатывать даты отдельно (фрагмент ПЕРВОГО МАЯ не означает “май с номером один” ! ).
Хотя морфологический словарь пока не имеет поддержки для имен собственных (они вводятся как обычные существительные), “имена собственные” возникают во время синтаксического анализа, когда группируется фрагмент текста, заключенный в кавычки. При семантическом анализе таких фрагментов необходимо, с одной стороны, сохранить фрагмент целиком (на это полное имя могут ссылаться другие документы), а с другой — желательно все-таки проанализировать смысловую структуру этого имени, чтобы этот фрагмент мог быть найден по неполному естественно-языковому запросу.
Решением этого противоречия является использование семантических пространств. Будем считать, что весь документ анализируется в пространстве Р1, данное предложение — в пространстве Р2, а имя собственное — в отдельном пространстве Р3, причем Р1 О Р2 О Р3. Тогда в пространстве Р2 будет создана одна вершина, содержащая полное имя собственное (например, “ЗАКОН ОБ АВТОРСКОМ ПРАВЕ”), а в пространстве Р3 — вершины “ЗАКОН”, “АВТОРСКОЕ ПРАВО”, и т. д. Кроме того, проведем отношение “имя” от вершины с полным именем собственным к любой вершине из пространства Р3.
Если имя собственное содержит внутри себя другие имена собственные (например, “ПОСТАНОВЛЕНИЕ О ПОРЯДКЕ ВВЕДЕНИЯ В ДЕЙСТВИЕ “ЗАКОНА ОБ АВТОРСКОМ ПРАВЕ””), то их аналогичным образом можно рассматривать в пространствах Р4 , Р5 и т. д.
Как уже говорилось, основной структурой данных для семантического анализатора является семантическая сеть. В памяти она хранится в виде двух динамических массивов — один для вершин, другой для ребер.
Словарная поддержка семантического анализа включает в себя: словарь моделей управления (файл CMODEL.TBL), словарь метапонятий (файл METAWORD.TBL) и словарь семантических ролей (файл SEMROLE.TBL).
Модель управления представляется динамическим массивом, каждый элемент которого (так называемая элементарная МУ) является записью.
Каждая элементарная МУ интерпретируется следующим образом: на данную семантическую роль может подойти слово с указанными морфологическими параметрами, сочетающееся с любым из указанных предлогов (если есть), при этом слово должно иметь ссылку на указанное метапонятие.
Все модели управления хранятся в динамическом массиве, который считывается из файла CMODEL.TBL при инициализации семантического анализатора. Удалять элементы из этого массива нельзя, поскольку все предикаты и ребра семантической сети ссылаются на соответствующие модели управления по их порядковому номеру.
Метапонятия предназначены для выражения обобщенных понятий, которые используются моделями управления в качестве ограничений. Никакой иерархической структуры метапонятий в данный момент не поддерживается. Однако каждое слово-понятие может иметь до десяти ссылок на различные метапонятия (поля SemLink[0] ... SemLink[9]). Таким образом, можно в явном виде указывать их иерархию, причем индивидуально для каждого слова ! Например, для понятия ЗАКОН сделать последовательно ссылки на метапонятия ДОКУМЕНТ, ТЕКСТ, ИНФОРМАЦИЯ, ОБЪЕКТ, а при реализации механизма поиска считать, что каждая следующая ссылка является обобщением предыдущей.
Все метапонятия хранятся в динамическом массиве, который считывается из файла METAWORD.TBL при инициализации семантического анализатора. Метапонятия могут свободно удаляться и добавляться в массив, поскольку имеют уникальные идентификаторы; все ссылки на метапонятия указывают не порядковый номер в массиве, а идентификатор.
Семантические роли характеризуют связи между предикатом и его актантами, а также между другими вершинами семантической сети. В отличие от большинства известных ЛП в данном проекте используется расширяемый, а не фиксированный список семантических ролей; это оказалось возможным из-за того, что механизмы интерпретации и поиска в семантической сети вынесены за пределы настоящей разработки.
Семантические роли представляются записями со структурой, аналогичной структуре метапонятия:
Все семантические роли хранятся в динамическом массиве, который считывается из файла SEMROLE.TBL при инициализации семантического анализатора. Как и для метапонятий, в этом массиве допускается свободное добавление и удаление записей.
Для доступа к словарю моделей управления служит диалоговое окно, реализованное в файле CMDLG.PAS. Это окно может одновременно показывать только одну модель управления. Для перехода к другой МУ служит поле в правом верхнем углу; в этом поле указывается номер требуемой модели управления.
Модель управления представляется в окне в виде таблицы, строки которой показывают элементарные МУ. Каждое поле элементарной МУ доступно для редактирования; при этом только поле “Предлог” вводится с клавиатуры вручную, а остальные поля выбираются при помощи вспомогательных диалоговых окон. Для добавления и удаления элементарных МУ служат две кнопки в нижнем левом углу окна.
Для создания новой модели управления служит кнопка “Новая МУ”, расположенная посередине в нижней части окна. Новая модель управления получает номер, на единицу больший общего количества МУ в словаре, и изначально не содержит ни одной элементарной МУ.
Просмотр и редактирование словаря метапонятий осуществляется с помощью диалогового окна, реализованного в файле MWDLG.PAS. Окно содержит список имеющихся метапонятий, а также кнопку “Новое...”, которая используется для ввода новых метапонятий. При нажатии на нее в список метапонятий добавляется еще одна строка, изначально пустая. В ней пользователь может ввести имя нового метапонятия; до тех пор пока не будет нажата кнопка “Выход”, это имя остается доступным для редактирования.
Для просмотра и редактирования словаря семантических ролей служит диалоговое окно, реализованное в файле SRDLG.PAS. Это окно полностью аналогично окну словаря метапонятий, с одним исключением: список показывает не только имена семантических ролей, но и их атрибуты (пока их два: симметричность и транзитивность). Двойной щелчок мышью на соответствующей клетке таблицы устанавливает или сбрасывает эти атрибуты.
Просмотр и редактирование результатов анализа
Как и для предыдущих этапов анализа, окно просмотра/редактирования семантической сети выполнено немодальным. Оно может представлять семантическую сеть двумя способами: либо в виде списка вершин, для каждой из которых показываются все инцидентные ребра и соответствующие смежные вершины, либо в виде списка ребер, с указанием начальной и конечной вершины для каждого ребра. Для переключения между этими режимами служат две “странички” диалогового окна. В режиме просмотра вершин есть возможность добавлять и удалять вершины (с помощью двух кнопок в нижней части окна), а в режиме просмотра ребер — добавлять и удалять ребра. Для каждого добавляемого ребра из списка вершин выбираются начальная и конечная вершины, а из словаря семантических ролей — имя ребра. Можно также вводить ребра с новыми именами, которых нет в словаре семантических ролей. Однако для того чтобы такие ребра впоследствии (на этапе поиска) могли быть обработаны, их необходимо будет занести в словарь семантических ролей.
Для удобства просмотра сети окно может изменять свои размеры. При этом размеры и положение всех списков и кнопок автоматически приводятся в соответствие с новыми размерами окна.
Поскольку окно результатов синтаксического анализа также немодальное, при нажатии в этом окне на кнопку “Следующий” можно в окне семантической сети наблюдать результат семантического анализа для очередного варианта разбора текста.
Заключение
Поиск в базе данных выполняется на основе совпадения (или некоторого соответствия) семантических структур пользовательского запроса и хранимого документа. Организованный таким способом поиск (будем называть его семантическим) обеспечивает гораздо более высокую точность и полноту, чем традиционный поиск по ключевым словам. Однако реализация семантического поиска, очевидно, является существенно более трудоемкой, чем реализация поиска по ключевым словам. Наиболее сложным для разработки элементом здесь является именно лингвистический процессор.
- Ю. М. Смирнов, А. М. Андреев, Д. В. Березкин, А. В. Брик. Об одном способе построения синтаксического анализатора текстов на естественном языке // Изв. вузов. Приборостроение, 1997. Т. 40, № 5 — стр. 34—42.
- Компьютерный синтаксический анализ: описание моделей и направлений разработок.— Г. Д. Карпова, Ю. К. Пирогова, Т. Ю. Кобзарева, Е. В. Микаэлян. // Итоги науки и техники (серия “Вычислительные науки”). Т.6. —М.: ВИНИТИ, 1991.
- Перспективы развития вычислительной техники: В 11 кн.: Справ. пособие / под ред. Ю. М. Смирнова. Кн. 2. Интеллектуализация ЭВМ / Е. С. Кузин, А.И. Ройтман, И. Б. Фоминых, Г. К. Хахалин. — М.: Высш. шк., 1989.
- Искусственный интеллект. — В 3-х кн. Кн.1. Системы общения и экспертные системы: Справочник. /Под ред. Э.В.Попова. —М.: Наука, 1990.
- Искусственный интеллект. — В 3-х кн. Кн.2. Модели и методы: Справочник. /Под ред. Д.А.Поспелова. —М.: Наука, 1990.
- Попов Э.В. Общение с ЭВМ на естественном языке. —М.: Наука, 1982.
- Интеллектуальные системы автоматизированного проектирования БИС и СБИС / В.А. Мищенко, Л.М. Городецкий, Л.И. Гурский и др.; Под ред. В.А. Ми щенко. - М.: Радио и связь, 1988.- 272 с. - стр.109 - 125.
- Рубашкин В.Ш. Представление и анализ смысла в интеллектуальных информационных системах. —М.: Наука, 1989.
- Буч Г. Объектно-ориентированное проектирование с примерами применения. —К.: Диалектика, 1993.