РАЗРАБОТКА МНОГОПОТОЧНОГО СЕРВЕРА СУБД ДЛЯ WINDOWS NT Omne nimium nocet… Все лишнее вредно… (лат.) А.М.Андреев, к.т.н., доц. МГТУ им. Н.Э.Баумана, Д.В.Березкин, к.т.н., директор НПЦ "ИНТЕЛТЕК ПЛЮС ", Ю.А.Кантонистов, ведущий разработчик НПЦ "ИНТЕЛТЕК ПЛЮС", Р.С.Самарев, студент МГТУ им. Н.Э.Баумана, контактный тел. (095) - 177 -80 -28 Введение Системы управления базами данных (СУБД) имеют большое значение в нашей жизни. До тех пор, пока их использовали для выполнения ограниченного круга задач при небольшом количестве пользователей, учитывая также ограниченные возможности вычислительных систем, проблема параллельной обработки запросов не возникала. Современная СУБД может использоваться большим количеством пользователей, работающих одновременно. Примером такого использования СУБД может служить система "АСУ-Экспресс". Для того, чтобы обеспечить одновременную работу большого количества пользователей в нормальном режиме (при минимальных временных задержках) необходимо применить либо высокопроизводительные однопроцессорные вычислительные системы при последовательной обработке запросов, либо менее производительные (по скорости выполнения обычных операций) многопроцессорные системы и параллельную обработку запросов, что является экономически более выгодно, по причине простоты увеличения производительности за счет числа процессоров. Современные операционные системы (ОС) такие как UNIX-системы, Windows NT обеспечивают возможность работы в многозадачном режиме и использовать для работы многопроцессорные системы. СУБД ODB-Jupiter является объектной СУБД, позволяющей вести работу в многопользовательском режиме с несколькими базами данных [1]. Обеспечивается совместный доступ нескольких пользователей к документам одной базы данных, а также совместный доступ нескольких пользователей к документам разных баз данных. Каждая база данных ODB-Jupiter физически состоит из двух файлов: файла данных, в котором собственно и хранятся все данные, содержащиеся в БД, а также индексного файла, который обеспечивает быстрый поиск необходимых данных. Выбор операционной системы В течение последних лет наблюдается устойчивый рост популярности операционной системы Windows NT, особенно это справедливо для России. Такой выбор обусловлен как историческими причинами (популярность ОС подобных MS-DOS, появление графического интерфейса Windows т.е. Win16), а также простотой реализации программ различного назначения (имеется достаточно большой набор средств разработки и комплектов документации). В данной статье будет рассматриваться ОС Windows NT версии 4.0 [2]. ОС Windows 95/98, а также WIN32S для Windows 3.11 не рассматриваются, так как не могут использовать ресурсы многопроцессорных систем. Подсистема WIN32 является достаточно мощным средством для выполнения широкого круга задач, а в частности для параллельной обработки данных. При этом нет необходимости распределять задачи по процессорам, выделять на них процессорное время - все это функции ОС. Введение в многозадачность Windows NT Для ОС Windows NT имеет место следующая классификация многозадачности:
При работе многозадачных программ требуется обеспечивать синхронизацию выполнения отдельных действий, таких как доступ различных задач (имеется в виду абстрактная самостоятельно выполняемая задача) к общим данным в определенной последовательности. Это может выть поочередный доступ к данным на запись и считывание, поочередная запись в одни и те же файлы и т.д. Для ОС Windows95/NT наиболее распространены в использовании следующие объекты синхронизации:
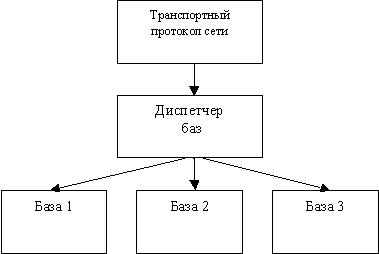
При необходимости изменить значение какой-либо переменной, не опасаясь, что за время обращения одного потока - другие потоки могут также попытаться изменить значение, нет необходимости использовать вышеперечисленные объекты синхронизации. WIN32 имеет соответствующие функции, позволяющие соответственно увеличить, уменьшить или присвоить конкретное значение переменной: InterlockedDecrement, InterlockedIncrement, InterlockedExchange. Функции, предназначенные для управления многозадачностью, как и другие системные, находятся в динамической библиотеке Kernel32.dll. Список все стандартных функций указан в WIN32 API. Реализация параллельной обработки запросов Использование процессов для обеспечения параллельной обработки данных сервером СУБД позволяет избежать их взаимного влияния друг на друга в случае возникновения исключительной ситуации (сбоя) в одном из них. ОС обеспечивает изоляцию адресного пространства процессов, т.е. при сбое памяти (запись/чтение невыделенной памяти) в адресном пространстве одного процесса не оказывается влияния на другие процессы. ОС обеспечит корректное завершение сбойного процесса. Для ОС процессы являются объектом, на который расходуется достаточно много системных ресурсов. Время создания объекта типа процесс также велико. Таким образом, построение параллельной обработки данных на процессах оправдывает себя только в случаях длинных по времени запросов или необходимости обеспечить высокий уровень защищенности программы от сбоев. Структура программы получается достаточно сложная. Все данные изолированы, однако ОС предоставляет возможность иметь процессам единые данные посредством механизма проецирования файлов в память. Передача данных от одного процесса к другому возможна только с использованием механизмов синхронизации, иначе не будет возможности определить момент изменения данных. Идеальный вариант для использования процессов - случай, когда единственное, что необходимо - совместный доступ на чтение к файлам базы данных (БД). Это могут быть, например поисковые запросы, или запросы на чтение содержимого БД. Использование потоков для обеспечения параллельной обработки данных сервером СУБД принципиально не позволяет исключить взаимное влияние при сбое потоков друг на друга. Однако потоки располагаются адресном пространстве одного процесса. Это позволяет им иметь общие данные, что значительно упрощает построение программы. Программа получается более экономичной по затратам памяти. Возрастает также скорость работы - создание потока менее длительная операция, чем создание процесса. При изменении общих данных также как и в случае с процессами, необходимо применять механизмы синхронизации. Но для потоков применим механизм синхронизации посредство критических секций. Это наиболее быстрый механизм синхронизации, поскольку поддерживается на уровне процессора. Для потоков также существует механизм защиты от сбоев. Язык С++ обеспечивает механизм структурной обработки исключений ( блоки try{…} catch(..){ throw(...);}) [3]. Также существует механизм обработки необработанных исключений Windows. Он позволяет установить собственный фильтр обработки исключений и корректно обработать ошибку. Обеспечивается это функциями AbnormalTermination, GetExceptionCode, GetExceptionInformation, RaiseException, SetUnhandledExceptionFilter, UnhandledExceptionFilter. Волокна, как уже упоминалось выше, являются наиболее простыми объектами. Таким образом, именно с помощью волокон можно добиться наивысшей производительности программы. Волокна по своим свойствам подобны потокам. Однако, по причине необходимости ручного администрирования, значительно возрастает сложность программы. Программный продукт ODB-Jupiter for Windows 95/NT разрабатывался как многопользовательская СУБД. Для организации параллельной обработки запросов рассматривались варианты использования процессов и потоков. Использование волокон не предусматривалось, поскольку требовалась совместимость с ОС Windows 95. Использование процессов рационально только при требовании устойчивости программы и сравнительно большом времени выполнения запроса (значительно превышающем время запуска самого потока). СУБД ODB-Jupiter организована таким образом, чтобы время выполнения одного действительного запроса было минимальным (это было необходимо при последовательной обработке запросов, чтобы при работе не было заметного времени ожидания ответа клиентами). Таким образом для СУБД ODB-Jupiter наиболее рациональным оказалось использование потоков. Классификация запросов для сервера ODB Сервер ODB обеспечивает обработку двух основных типов запросов: запросы на чтение данных и запросы на модификацию данных БД. К запросам на чтение данных относятся поисковые запросы, запросы на считывание различных структур БД таких как запросы на чтение документов или чтение структуры рубрикатора. К запросам на модификацию данных БД относятся запросы на добавление, удаление или изменения документов БД, добавление новых типов документов и другие. Реализация параллельной обработки запросов сервером ODB СУБД ODB-Jupiter является чисто объектной СУБД. Программы, реализующие ее внутренние механизмы удовлетворяют принципам объектно-ориентированного программирования (ООП). В общем виде организация взаимодействия объектов (см. Рис. 1) такова: Объект базы данных содержит все необходимые ему данные о подключенных клиентах. Организовано это также в виде объекта. Для каждого клиента заводится объект, содержащий объекты, которые осуществляют работу с фалом данных и индексным файлом данной БД, а также ряд специальных объектов, таких как объект с параметрами языка, с которым работает пользователь (используется для полнотекстового поиска).
Рис. 1. Общая схема взаимодействия объектов и передачи запросов. Сервер OBD обеспечивает параллельную обработку запросов на чтение в пределах одной базы данных и полную параллельность работы запросов для разных баз данных (включая модификацию БД). Полная параллельность обработки запросов на одной БД не обеспечивается по причине сложности алгоритмов одновременной модификации файлов БД, в частности индексного файла. Поскольку основная масса запросов, поступающих на сервер - запросы на чтение данных, то разработка и применение алгоритмов, позволяющих вести одновременную модификацию данных, на данной стадии развития проекта признана нецелесообразной. Один из способов одновременной модификации данных совместно с чтением данных - копирование участка, который подлежит модификации, его модификация и последующая замена старых данных. Этот способ применим только в том случае, если не поступило несколько запросов на модификацию данных во взаимоперекрывающихся участках данных. Тогда обработка запросов выливается в последовательную обработку. Следовательно, в случаях, если монопольное использование БД одним клиентом в течении нескольких секунд не является проблемой (при относительно небольшом числе модифицирующих данные клиентов), целесообразно применять полное блокирование БД для других клиентов на время модификации. Полная параллельность обработки запросов достигается на разных БД. Это обеспечивается взаимной независимостью файлов БД на разных БД. Модификация файлов одной БД не влияет на обслуживание запросов в другой БД. Разделение обслуживания запросов клиентов производится на уровне получения данных от транспортного протокола сети. На этом уровне данные являются "сырыми", т.е. это блок данных, содержащий помимо основных данных служебную информацию. Их обработка уже может производиться параллельно. На этапе первичной обработки данных производится определение имени БД, к которой адресован запрос. Диспетчер БД направляет этот запрос объекту конкретной БД, где запрос подвергается окончательной обработке. На этом уровне производится блокирование запросов, которые не могут быть выполнены одновременно (при блокировании обработка запросов производится последовательно в порядке их поступления на сервер). Как уже упоминалось выше, запросы модификации БД блокируют начало обработки остальных запросов вплоть до завершения их обработки. Для этих целей каждый объект БД имеет поле критическую секцию. Конструктор объекта БД производит инициализацию критической секции, деструктор - удаление. Фрагмент файла класса БД: WINSOCKDATA* TSdbDatabase::Dispatch(…) { …EnterCriticalSection(&Critical_section); …switch (iCmd) {//выбираем по коду операции метод-приемник { …case dbCmd_Del: for(;wRead_operations_Count;); Del (lpTransfer,i); LeaveCriticalSection(&Critical_section); break; case dbCmd_Read: wRead_operations_Count++; LeaveCriticalSection(&Critical_section); Read (lpTransfer,i); InterlockedDecrement( reinterpret_cast<LPLONG>(&wRead_operations_Count)); break; } В приведенном фрагменте программы показана реализация метода класса TSdbDatabase, выполняющего распределение выполняемых действий по коду операции, пришедшего от клиента. Переменная wRead_operations_Count является полем класса TsdbDatabase. Ее назначение - определение факта выполнения операций чтения в данный момент (если нуль - ничего не выполняется). Начальное значение - нуль. Вход в критическую секцию выполняется в непосредственной близости от вызова методов, выполняющих обработку данных. Это сделано для минимизации времени нахождения потока в критической секции при операциях чтения, а также для обеспечения блокировки в операциях записи. В приведенном примере случай dbCmd_Del - операция записи. Первое действие перед началом удаления данных - ожидание в бесконечном цикле for(;wRead_operations_Count;); обнуления переменной wRead_operations_Count. Только после завершения выполнения всех операций чтения из это БД в других потоках, производится вызов метода, выполняющего удаление данных. И только после его завершения происходит выход из критической секции. В случай операции чтения (в приведенном примере - случай dbCmd_Read) в пределах критической секции производится увеличение значения переменной wRead_operations_Count (пользуясь тем, что другие потоки в данном участке программы в это время выполнятся не могут). Сразу за операцией инкремента следует выход из критической секции. И только после этого - вызов метода обработки данных. После завершения обработки данных необходимо уменьшить значение переменной wRead_operations_Count, однако исполняемый код находится уже за пределами критической секции. Таким образом для гарантированного правильного изменения этой переменной применяется функция InterlockedDecrement. Принцип работы блокировки в одной БД поясняет приведенная ниже Таблица. Она отражает диаграмму процесса обработки различных запросов потоками при одновременном из выполнении (за вычетом времени поступления сообщения от транспортного протокола).
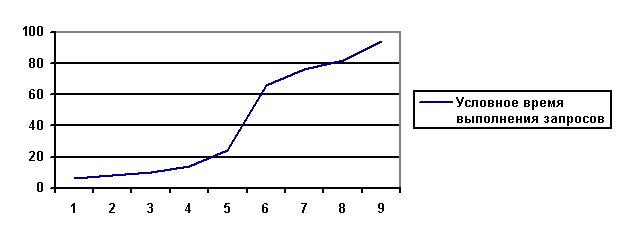
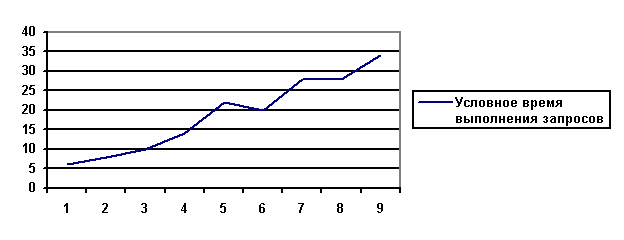
В организованном таким образом участке программы обеспечивается минимальная задержка на операциях чтения (к тому же надо учитывать, что одновременное поступление запросов от нескольких клиентов невозможно по причине последовательной работы транспортного протокола сети). Вычислительная нагрузка ЭВМ При одновременном обслуживании нескольких клиентах необходимо помнить об ограниченных вычислительных мощностях системы, т.е. при некотором количестве одновременно выполняемых запросов происходит значительное снижение производительности ЭВМ. Обусловлено это тем, что ОС пытается равномерно распределить системные ресурсы по выполняемым потокам. Однако, в случае большого количества ресурсоемких потоков ОС не может выделить "одновременно" требуемого количества ресурсов, например, достаточного процессорного времени или физической памяти. Для предотвращения перегрузки вычислительных мощностей системы необходимо обеспечивать одновременное выполнение ограниченного числа запросов. WIN32 содержит механизм, позволяющий это осуществить - семафоры. Семафор, как уже говорилось выше, допускает в ограничиваемую секцию потоки до тех пор, пока счетчик не обнулен. Все остальные потоки, пытающиеся выполнить код, находящийся в ограниченной секции, ждут освобождения семафора. Изменение счетчика возможно на любое значение. Таким образом помимо ограничения общего количества одновременно выполняемых запросов, возможно разделение запросов на более и менее ресурсоемкие. В СУБД ODB-Jupiter производится ограничение одновременного выполнения запросов на уровне диспетчера баз. В принципе, можно было бы производить это ограничение на уровне приема данных от транспортного протокола, но, поскольку требуется освобождение семафора после завершения выполнения запроса, с программной точки зрения рациональнее делать это в пределах одной функции. Для СУБД ODB-Jupiter была проведена оценка производительности (под производительностью понимается суммарное время выполнения всех поданных запросов) при разном количестве одновременно обрабатываемых запросов и общем количестве поданных запросов. Измерения времени выполнения всех запросов производились на двухпроцессорной системе с процессорами Pentium II. Ниже приведены два графика времени выполнения одинаковых поисковых запросов (запросы на чтение) в зависимости от количества запросов. На первом графике (Рис. 2) приведены зависимость времени выполнения запросов от количества одновременно выполняемых запросов, на втором (Рис. 3) - суммарное время выполнения всех запросов от количества поданных на сервер запросов при условии одновременного выполнения не более 4-х. Поскольку время выполнения запроса зависит от самого запроса, будем выражать полученное значение времени в некоторых условных единицах.
Рис. 2. Условное время выполнения всех запросов в зависимости от их количества. На графике показано условное время одновременного выполнения запросов в зависимости от их количества. Очевидно явное снижение производительности при выполнении более 5-ти запросов одновременно. При этом наблюдается нелинейная зависимость снижения производительности.
Рис 3.Условное время выполнения всех одновременно поступивших запросов в зависимости от их количества при ограничении одновременного выполнения 4 запросов. Приведенный на рис.3 график показывает увеличение производительности системы уже на 9 запросах более чем в 2 раза. На графике различимы моменты увеличения производительности при одновременной обработке количества запросов кратного числу процессоров. При этом одновременно обрабатывается 4 запроса - остальные ждут. Таким образом, оптимальная производительности достигается при одновременно выполняемом числе запросов не более чем 2.(число процессоров сервера, на котором проводились эксперименты). Суммарное время выполнения всех запросов имеет в данном случае практически линейную зависимость (если не учитывать локальные моменты увеличения производительности). Заключение При разработке современной СУБД необходимо помнить о возрастающих требованиях к скорости работы СУБД, а также эффективно использовать существующие средства операционных систем. Рассмотренный метод реализации параллельной обработки, основанный на использовании потоков для обеспечения параллельной обработки данных сервером СУБД, является достаточно простым и универсальным для реализации. Литература 1. Андреев А.М., Березкин Д.В., Кантонистов Ю.А., Смирнов Ю.М. “Объектно-ориентированная база данных ODB-Jupiter”//Приборостроение”, №1, 1998 г. 2. К.Ивенс. Windows NT Workstation 4. Внутренний мир. Диасофт-Киев, 1997 г. 3. Руководство программиста по Microsoft Windows 95, Microsoft Press, Русская редакция, 1998 г.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||